Universal Dependencies tools
This page collects links to and minimal instructions for tools related to Universal Dependencies.
If you would like to have your tool added to this page, please write the UD mailing list.
Listing
- Tools maintained by the UD project
- Annotation statistics
- Consistency checking
- Data validation
- Format conversion
- Third-party tools
UD-maintained tools
The Universal Dependencies project maintains a number of core tools for working with UD data. These tools are available from https://github.com/universaldependencies/tools and briefly described below.
Annotation statistics
There are two scripts that compute statistics, one written in Python and one in Perl. Despite similar names they are not equivalent!
python conllu-stats.py -h python conllu-stats.py --stats ../UD_English/en-ud-train.conllu perl conllu-stats.pl --help
The Perl script can be run in two main modes. In the default mode, it generates a XML file with statistics, including all tags, features and relations. This file is generated by the release team for every released treebank and the file stats.xml is then part of the release. The script is typically invoked from the treebank folder:
cat *.conllu | perl conllu-stats.pl > stats.xml
In the other mode, the script generates much more detailed statistics, which are then automatically included at appropriate places of the language-specific documentation. In this case the script needs to know where are all the treebank repositories and where is the docs repository. It will process all treebanks of one language in one run because there is only one docs section per language. It will write the statistics to the docs repository, which must be switched to the pages-source branch and must be afterwards pushed back to Github. This is usually also done at release time for all languages.
perl conllu-stats.pl --detailed --data .. --docs ../docs --lang pt
Consistency checking
(Description TODO)
Data validation
(Description TODO)
Format conversion
See Issue 376 for references to software that helps with migration of treebanks from UD v1 to v2 guidelines.
Third-party tools
brat rapid annotation tool
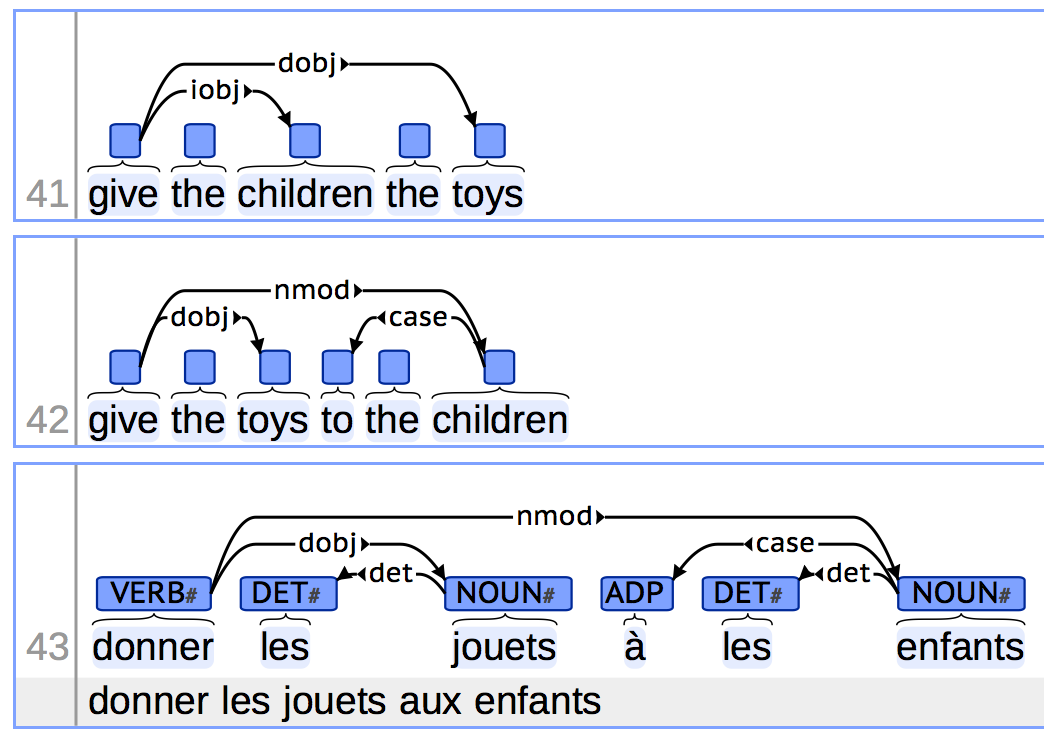 brat is a browser-based tool for text annotation. The brat visualization component is used in the UD documentation system and the tool comes with a custom configuration allowing it to be used for UD annotation .
brat is a browser-based tool for text annotation. The brat visualization component is used in the UD documentation system and the tool comes with a custom configuration allowing it to be used for UD annotation .
- Category: manual annotation tool
- Platform: any (browser-based)
- Implementation: Python (server), JavaScript (client)
- License: MIT (open source)
- Homepage: http://brat.nlplab.org/
- References: Stenetorp et al. (2012)
CL-CoNLLU
A Common Lisp library for various CoNLL-U-related operations. We have already functions for reading, writing, making queries, construct visualizations of sentences, compare trees etc.
- Category: library
- Platform: any SO that runs a Common Lisp implementation
- Implementation: Common Lisp
- License: Apache License
- Homepage: https://github.com/own-pt/cl-conllu/
- References: http://arademaker.github.io/bibliography/tilic-stil-2017.html
CoNLL-U viewer
A simple browser-based (JavaScript, i.e. client side) viewer of your CoNLL-U files. Open your file, see the tree, go to the next tree. Click on a node to see all its attributes. Save the tree as an SVG graphics if needed. There is no way of jumping directly to a tree, neither by tree number, nor by searching attribute values.
- Category: tree viewer
- Platform: any (browser-based)
- Implementation: JavaScript
- Credit: Milan Straka, Michal Sedlák
- Access here
DKPro Core CoNLL-U reader/writer
DKPro Core is collection of software components for natural language processing (NLP) based on the Apache UIMA framework. DKPro Core can be used to build workflows that automatically process text using a wide range of NLP tools from third parties that are all interoperable (Stanford CoreNLP, Apache OpenNLP, ClearNLP, mate-tools, etc etc.). It also supports a range of different data formats and can be used to convert between the different supported formats.
Starting with version 1.9.0, DKPro Core supports reading and writing the CoNLL-U format.
The latest CoNLL-U 2.0 format is not yet supported.
- Category: UIMA component
- Platform: Windows, Linux, OS X
- Implementation: Java
- License: Apache License 2.0 (open source)
- Homepage: https://dkpro.github.io/dkpro-core/
- References: see DKPro Core website
Treex
Treex is a modular natural language processing framework. It reads and writes data in many formats (including CoNLL-U) and provides API for dependency tree manipulation. Many treebanks have been harmonized in HamleDT and then converted to UD using Treex.
- Category: treebank processing framework
- Platform: tested mainly on Linux
- Implementation: Perl
- License: Perl
- Homepage: http://ufal.mff.cuni.cz/treex
- References: Popel and Žabokrtský (2010)
Tred
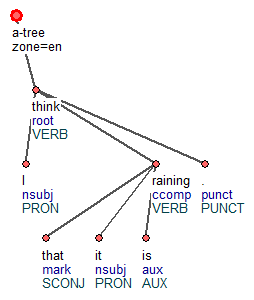 Tred (Tree Editor) is a graph visualization and manipulation program written in Perl. It was the main tool used to annotate the Prague treebanks. It supports macros (in Perl) to automate frequently repeated operations. There are extensions for various annotation layers such as MWEs or coreference. It cannot read directly the CoNLL-U format. However, it is quite powerful in combination with Treex, which can also convert the files from and to CoNLL-U.
Tred (Tree Editor) is a graph visualization and manipulation program written in Perl. It was the main tool used to annotate the Prague treebanks. It supports macros (in Perl) to automate frequently repeated operations. There are extensions for various annotation layers such as MWEs or coreference. It cannot read directly the CoNLL-U format. However, it is quite powerful in combination with Treex, which can also convert the files from and to CoNLL-U.
- Category: manual annotation tool
- Platform: Windows, Linux, OS X
- Implementation: Perl
- License: GPL (open source)
- Homepage: http://ufal.mff.cuni.cz/tred/
- References: Petr Pajas, Peter Fabian
UDPipe
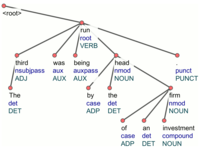 UDPipe is a trainable pipeline for tokenization, tagging, lemmatization and parsing of CoNLL-U files. UDPipe is language-agnostic and can be trained given only annotated data in CoNLL-U format. (Nevertheless, to train the tokenizer, either the
UDPipe is a trainable pipeline for tokenization, tagging, lemmatization and parsing of CoNLL-U files. UDPipe is language-agnostic and can be trained given only annotated data in CoNLL-U format. (Nevertheless, to train the tokenizer, either the SpaceAfter feature must be present, or at least some plain text must be available; also morphological analyzer and lemmatizer can be improved if morphological dictionary is provided.) Trained models are provided for nearly all UD treebanks. UDPipe is available as a binary, as a library for C++, Python, Perl, Java, C#, and as a web service.
- Category: trainable tokenizer, tagger, lemmatizer and parser
- Platform: Linux, Windows, OS X
- Implementation: C++; language bindings for Python, Perl, Java and C#
- License: MPL 2.0 (open source)
- Homepage: http://ufal.mff.cuni.cz/udpipe
- On-line service: http://lindat.mff.cuni.cz/services/udpipe/
- References: Milan Straka, Jan Hajič and Jana Straková 2016. UDPipe: Trainable Pipeline for Processing CoNLL-U Files Performing Tokenization, Morphological Analysis, POS Tagging and Parsing. LREC 2016, Portorož, Slovenia, May 2016.
UDAPI
- Category: libraries for various UD and CoNLL-U-related operations in several programming languages
- Implementation: Java, Perl, Python
- License: GPL, Perl
- Homepage: http://udapi.github.io/
WebAnno
WebAnno is a general purpose web-based annotation tool for a wide range of linguistic annotations including various layers of morphological, syntactical, and semantic annotations. Additionaly, custom annotation layers can be defined, allowing WebAnno to be used also for non-linguistic annotation tasks. WebAnno targets annotation teams in which all annotators work independently from each other. The tool includes facilities for curating/merging the annotations from multiple annotators, calculating inter-annotator agreement, and project management. Additional features include a correction and automation mode as well as decent support for right-to-left languages.
Since version 3.0.0, WebAnno supports importing and exporting data in the CoNLL-U format. If the data contains sub-token annotations, then the text is obtained from the subtokens and the surface text is added as annotations. To control which column dependencies end up in, the flavor feature of the built-in dependency layer needs to be used. If the feature is set to enchanced, then it goes to the enhanced dependencies column, otherwise to the basic dependencies column. It is currently up to the annotator to ensure that the dependency trees are well-formed and representable in CoNLL-U, otherwise export to CoNLL-U may fail.
WebAnno 3.0.0 does not support the CoNLL-U 2.0 format at this time.
- Category: manual annotation tool
- Platform: client: any (browser-based), server: Java
- Implementation: Java (server), JavaScript (client)
- License: Apache License 2.0 (open source)
- Homepage: https://webanno.github.io/webanno/
- References: see WebAnno website
DgAnnotator
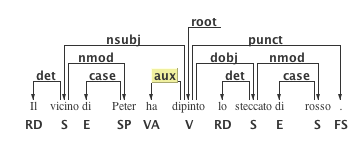 DgAnnotator (Dependency Graph Annotator) is a visual tool for annotating text with syntactic information, in particular creating a dependency tree. The tool reads and produces annotated documents in both XML, CoNLL-X and CoNLL-U tab separated format. Additional features: shows the differences, highlighted in red, between two different dependency trees on the same corpus; generates PNG snapshots of trees; performs PoS tagging and parsing connecting to a network service; panning and zooming.
DgAnnotator (Dependency Graph Annotator) is a visual tool for annotating text with syntactic information, in particular creating a dependency tree. The tool reads and produces annotated documents in both XML, CoNLL-X and CoNLL-U tab separated format. Additional features: shows the differences, highlighted in red, between two different dependency trees on the same corpus; generates PNG snapshots of trees; performs PoS tagging and parsing connecting to a network service; panning and zooming.
- Category: manual annotation tool
- Platform: Windows, Linux, OS X
- Implementation: Java
- License: GPL (open source)
- Homepage: http://medialab.di.unipi.it/Project/QA/Parser/DgAnnotator/
- References: Giuseppe Attardi
Arborator
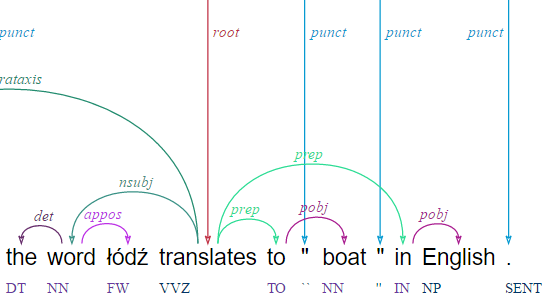 Arborator is a manual dependency annotation tool supporting editing of POS tags and dependency relations in an easy to use drag and drop interface. It has project management features including specialized class-sourcing features, such as mixing in small amounts of gold data for evaluation/grading and assigning tasks to annotators. It supports color schemes for different labels and can read and write conll format dependencies. It now supports conllu input as well. There is also a ‘quick mode’ that can be used without setting up a project, just be copy-pasting conll data. For a demo, see here: https://arborator.ilpga.fr/q.cgi
Arborator is a manual dependency annotation tool supporting editing of POS tags and dependency relations in an easy to use drag and drop interface. It has project management features including specialized class-sourcing features, such as mixing in small amounts of gold data for evaluation/grading and assigning tasks to annotators. It supports color schemes for different labels and can read and write conll format dependencies. It now supports conllu input as well. There is also a ‘quick mode’ that can be used without setting up a project, just be copy-pasting conll data. For a demo, see here: https://arborator.ilpga.fr/q.cgi
- Category: manual annotation tool
- Platform: Any
- Implementation: Python, JavaScript
- License: AGPL-3.0 (open source)
- Homepage: https://arborator.ilpga.fr/
- References: Gerdes, Kim (2013), Collaborative Dependency Annotation. In: Proceedings of the Second International Conference on Dependency Linguistics (DepLing 2013). Prague, 88–97.
Deptreeviz
- Category: tree visualization (SVG graphics)
- Platform: Any
- Implementation: Java
- License: Apache License 2.0 (open source)
- Homepage: https://gitlab.com/nats/deptreeviz
- References: Sven Zimmer, Arne Köhn